To access the per-archive preference settings, open an archive and choose ➤ from the menu.
Shifted quanta detection performs advanced data de-duplication analysis during capture. It looks for duplicate blocks of data that have been shifted (relative to their previous offset) in the file. This requires a lot more processing, but can produce significant storage savings for some types of documents.
At the lowest (leftmost) setting, no shifted quanta detection is performed. At the highest, every byte offset in every file is tested for shifted quanta.
The settings in between automatically throttle shifted quanta detection based on performance. Shifted quanta detection is periodically turned on during capture; if it is successful in saving archive space it is left on, or disabled again if it is not being effective.
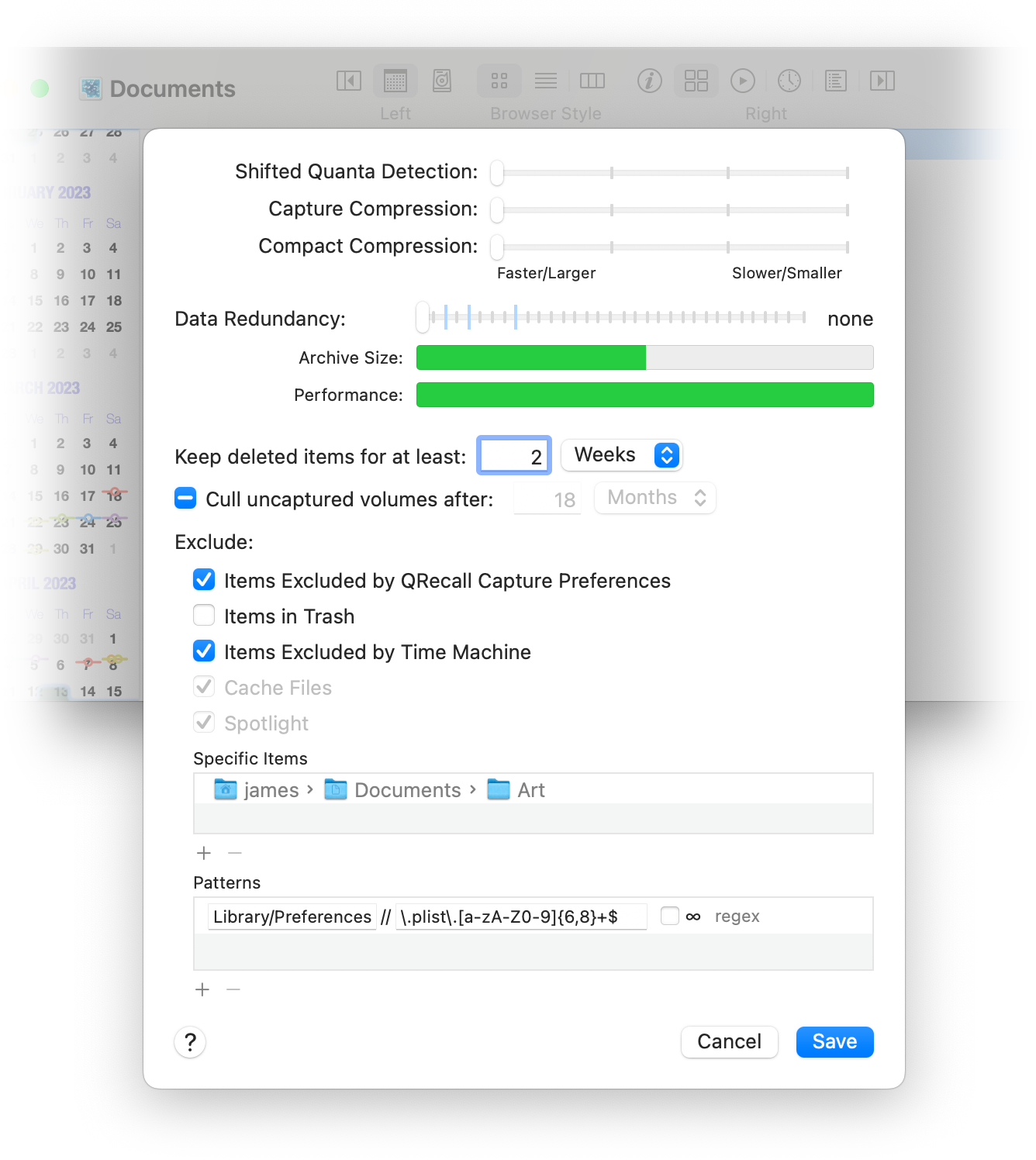
During capture, each file is divided into discrete blocks of data referred to as quanta.
When the file is recaptured, every quanta of data is compared to those already captured in the archive; if they are the same, no new data is added to the archive. This is what makes QRecall so phenomenally efficient when compared to backup solutions that blindly duplicate entire files.
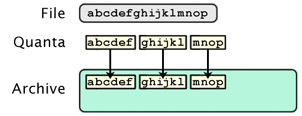
Now consider the situation where the data has been shifted (due to new data being inserted/deleted in the middle of the file). When the file is subdivided, all of the data blocks appear to be different, defeating the duplicate data matching. In this example, two chunks of data have been inserted at the beginning of the file. Without shifted quanta detection, the file appears to contain all new quanta, and the archive doubles in size:
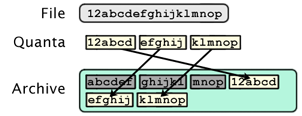
Shifted quanta detection works by searching for matching data blocks at every possible offset within the file:
If a shifted quanta is found, only the quanta surrounding it needs to be captured.
The amount of additional processing required to perform shifted quanta detection can't be overstated. When set to its highest level, the data analysis performed during capture can be over a hundred times slower than when turned off.
The benefits of shifted quanta detection can also vary wildly. Many files (log files, disk images, virtual machine files, and so on) do not benefit at all from shifted quanta detection. The files types that benefit the most are multimedia and graphic arts project files (video, Keynote, Photoshop, Illustrator, page layout, DVD authoring, and so on), where large amounts of unchanged data get rewritten at different locations within a file, or get duplicated in other files.
Recommendation:
The compression settings control how much, and when, data records in the archive are compressed.
Compression is the simplest way to reduce the size of an archive, but requires additional processing. Compression slows down the writing of new archive records. And once a record is compressed, it must be decompressed every time it is read.
On the other hand, compression might actually improve performance. When the archive is on a external or network storage device that has a particularly slow interface, reading and writing less (i.e. compressed) data can make archive operations faster. You can always compress an uncompressed archive later by setting a compression level and compacting the archive.
The Capture Compression setting controls the compression of new archive records as the are captured. The leftmost setting performs no compression at all, while the rightmost setting performs the most aggressive compression possible.
The Compact Compression setting controls the compression of uncompressed archive records during the compact action.
Setting the capture compression level performs the compression during capture. It's the most efficient way to compress records, but slows down the capture.
Setting the capture compression to off and the compact compression to a higher level defers compression until the archive is compacted; the capture runs faster, while the compact runs slower.
Like shifted quanta detection, the benefits of compression will vary depending on the nature of the data captured.
The level of compression sets QRecall's effectiveness tolerance:
At the lower levels, only large records are compressed and the compression must save a significant amount of data (12% or more) to be considered effective. If compression wasn't effective, the record is written without compression. In other words, QRecall chooses better performance over small amounts of compression.
The higher settings attempt to compress smaller records and tolerate poorer compression ratios, preferring small gains in compression over performance.
Compressed records are never written if, after compression, they would be larger than the original record.
The Data Redundancy setting shows the current data redundancy level for the archive. This is normally set when the archive is created, but you can alter it in the archive's settings.
If you alter the setting, new correction blocks will be calculated for the entire archive. This can be a time consuming process for large archives, very close to the amount of time it takes to verify it.
The leftmost setting means that the archive has no redundant data. Changing the setting to none will remove all correction blocks from the archive.
See data redundancy for more details.
The Keep deleted items for at least setting ensures that any item deleted within the "keep deleted" time period will be available for recall, as long as the item was captured at least once.
An item captured in one layer, and absent from the next layer (because it was discard or moved), is considered to be deleted in the archive. You can see, and recall, deleted items either by rewinding the archive to that earlier layer or using the ➤ command. See recalling deleted items.
When layers are merged, those deleted items are normally expunged from the archive. See merging layers. Setting the Keep deleted items for at least setting changes this behavior.
If a deleted item was deleted within the "keep deleted" time period, the item isn't physically removed when the layers are merged. Instead, the item is retained in the layer and marked "deleted." It does not appear in the archive item browser (unless said is on), and will not be recalled (again, unless is on)
Once a deleted item is older than the "keep deleted" time period, it is eventually removed from the archive when:
A setting of 0 (zero) will not preserve any deleted items.
A volume that was once captured, but is no longer being captured, can remain in the archive indefinitely.
To prevent old volumes from occupying space in the archive forever, the Cull uncaptured volumes after setting sets a limit on how long a volume can persist in the archive.
Volumes are culled by the compact action.
The decision to cull a volume is calculated by comparing the last time the volume was captured and the date of the most recently captured volume in the archive. If that time period exceeds this setting, then the volume is deleted (culled).
This means that a volume won't be removed if the archive is never compacted. It also won't be removed if new layers are not being added to the archive, no matter how old the volume is.
The Exclude settings collectively determine what items are excluded from being captured. These settings are applied to all future captures made to this archive.
The five checkboxes each exclude a pre-determined set of items:
/private/var/folders./.Spotlight-* and the database files in /private/var/db/Spotlight.Arbitrary items can be excluded by adding them to the a Specific Items list.
To add items you can't normally select in the Finder, hold down one or both of these modifier keys when clicking the + button:
QRecall remembers which items were excluded during the capture. If you later restore (overwrite) a folder that contained excluded items, then…
The primary advantage of using the archive's settings to exclude an item is that the item doesn't have to have a Do not capture preference setting in order to be excluded. This means you can exclude items that might be periodically deleted and recreated, or items on volumes that don't support extended attributes—situations where the per-item capture preferences can't help.
It can also be handy when you want to exclude an item from a specific archive, but let other archives capture it.
In most other cases, the per-item capture preference is the preferred method of excluding arbitrary items.
QRecall remembers excluded items using a bookmark. This is a standard macOS data structure used to remember the location of an item and locate it again later.
Be aware that bookmarks of items on the startup volume are often "relative" to that system, and may fail to locate the item—or even identify a different item—when QRecall is run on another system.
If you are capturing multiple systems to a single archive, use per-item capture preferences to exclude items whenever possible. If this is impractical, consider creating exclude patterns (which do not use bookmarks) for the items. You might also try to add items multiple times, once from each system being backed up, so the archive has a bookmark for that item relative to each system that wants to exclude it.
You can also exclude items by adding patterns. Patterns use glob (shell) file matching or regular expression syntax to match the names of items you want excluded.
See exclude patterns.
There are a number of items that are always excluded:
/private/var/tmp~/.TemporaryItems folders