All archives provide error detection. Redundancy adds error correction, empowering QRecall to tolerate modest amounts of unreadable or corrupted data.
The amount of redundant data is set when the archive is created. You can change it later in the archive's settings.
The slider controls the amount of redundant data that will be generated for the archive, expressed as a ratio. A setting of 1:16 will generate one byte of correction data for every 16 bytes of archive data. The maximum is 1:1, generating a byte of correction data for every byte of archive data, doubling the size of the archive.
The leftmost setting (none) generates no redundant data and disables error correction. Choose this setting if the volume that contains the archive provides its own error correction. Examples would be a RAID5 disk array or cloud storage service.
The two indicators show the effect the setting will have on the size and performance of the archive.
The ratio you choose can dramatically affect performance. Error correction requires a lot of matrix math; the dimensions of the matrices are determined by the ratio of correction data. Some ratios can be optimized, resulting in better performance. The ratios with the best performance are none, 1:16, 1:8, and 1:4; these ratios are highlighted in the slider.
Archive redundancy uses Reed-Solomon error correction. This is the most widely used error correction mechanism, and is the same method used by disk arrays, DVDs, and countless other applications.
When you choose a level of redundancy, QRecall generates correction code blocks for each cluster of data blocks in the archive. For example, selecting a 1:4 redundancy ratio might generate two correction code blocks for every eight data blocks in the archive:
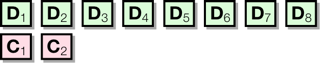
These correction code blocks are mathematical complements of the information in the data blocks. If a data (or correction) block is corrupted or unreadable, the information in the remaining blocks can be used to reconstruct the information that was lost:
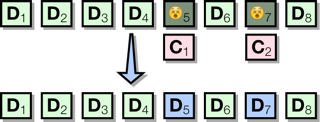
The limit of Reed-Solomon error correction is that the damage can't exceed the amount of redundant information. In the 1:4 example, there are two blocks of redundant data generated for every eight data blocks. So within that cluster of ten blocks, the archive can tolerate the loss of any two blocks (up to 20% of the original data). The loss of three or more blocks would result in permanent data loss.
Redundancy is a good defense against the occasional corruption of a data due to localized media failures, transmission errors, flaky hard drive controllers, memory bit flip errors, and so on. It will not protect against wholesale data loss, such as magnetic head alignment problems that will cause wide swaths of a hard drive become unreadable. Striped hardware solutions (like RAID5 or RAID6) are a much better defense against those types of failures.
QRecall writes the correction code blocks to a different set of files, and encourages the filesystem to store those files at a disassociated location on the disk. This reduces the possibility that a physical defect in the disk surface will corrupt both the data and its correction codes.
QRecall usually refers to the correction codes only when it detects corrupted or unreadable data. So for the most part, correction codes are not used until they are needed.
Here's a quick summary of when correction codes are used: