![]() A stack is a decomposed copy of an archive that can be stored on a remote device or cloud data service.
A stack can be incrementally synchronized with changes made to the archive to keep the copy up-to-date.
A stack can later be used to recreate or repair the original archive.
A stack is a decomposed copy of an archive that can be stored on a remote device or cloud data service.
A stack can be incrementally synchronized with changes made to the archive to keep the copy up-to-date.
A stack can later be used to recreate or repair the original archive.
Stacks are designed to:
Stacks are silent partners that you set and forget. Once set up, with any luck, you'll never need to interact with the stack again.
The contents of a stack are stored in a stack container. A stack container can be located in:
Unlike an archive, that is constantly being read and modified, the contents of a stack are organized into discrete data objects/files that are written once and infrequently replaced. This means that a stack container can be efficiently used on almost any cloud or remote file storage technology, even WebDAV.
Stacks, like archives, are organized into layers. The layers in a stack mean exactly what they mean in the archive.
When a stack is initial created, and the archive copied to it, there is a one-to-one correspondence between the layers in the archive and the layers in the stack.
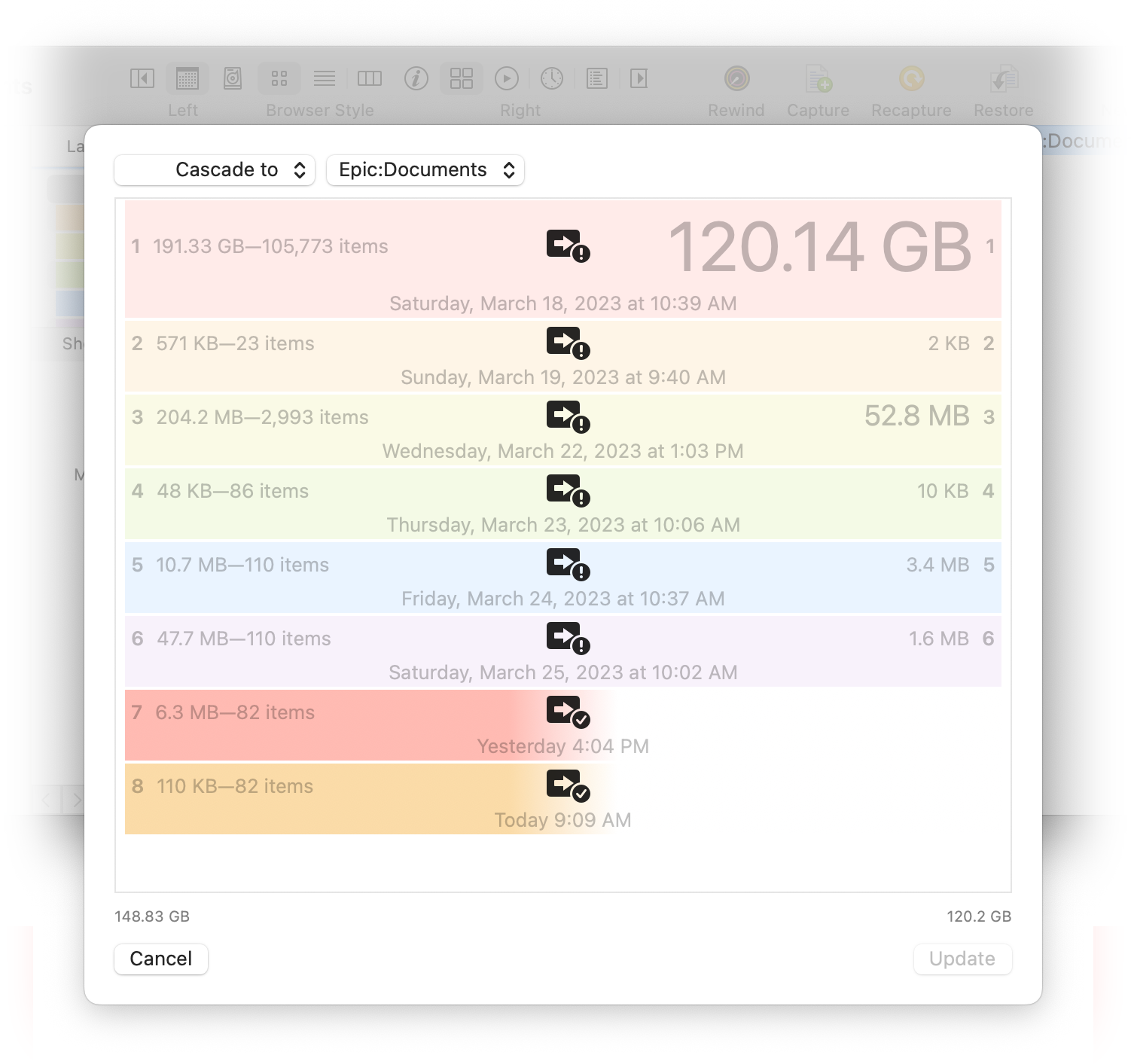
As the archive matures, layers are merged and items get removed. A single merged layer in the archive will represent the same change information stored in several layers of the stack (which are copies of the original layers before they were merged).
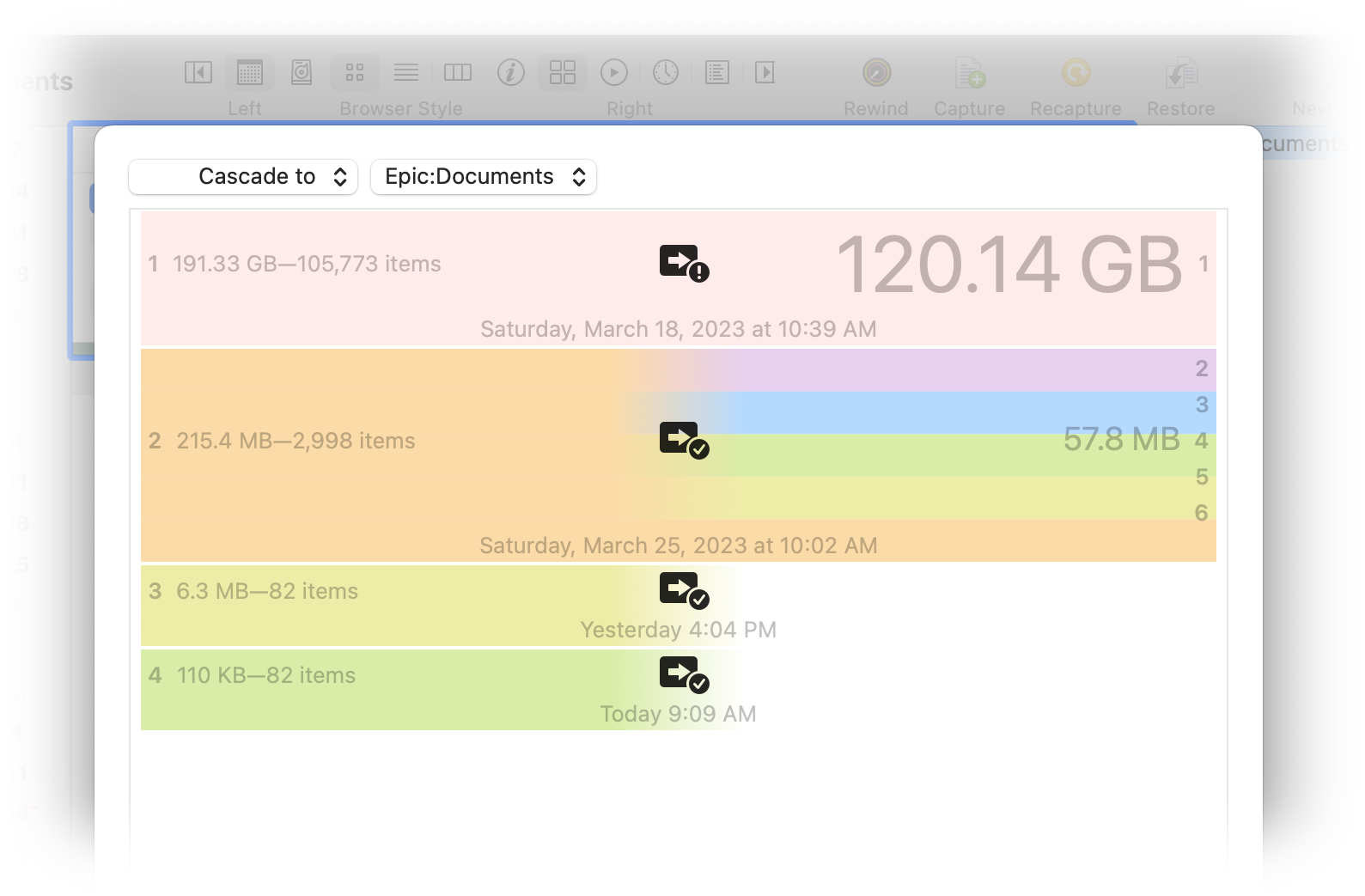
In the above example, the original layers 2—6 were merged into a single layer. Now layer 2 in the archive and layers 2—6 in the stack represent the same set of changes.
The merged layer in the archive and the copy of the original layers in the stack form a slice.
Important concept: all stack operations are performed on slices. A layer in a stack or archive can only be replaced with an equivalent layer or set of layers from the other.
If you then copy the merged layer in the archive to the stack, it will replace the set of layers in the stack representing the same set of changes. The stack has now been synchronized with the archive and is, again, a one-to-one copy of the archive data. This is called a "cascade" (changes flow into the archive and then down to the stack).
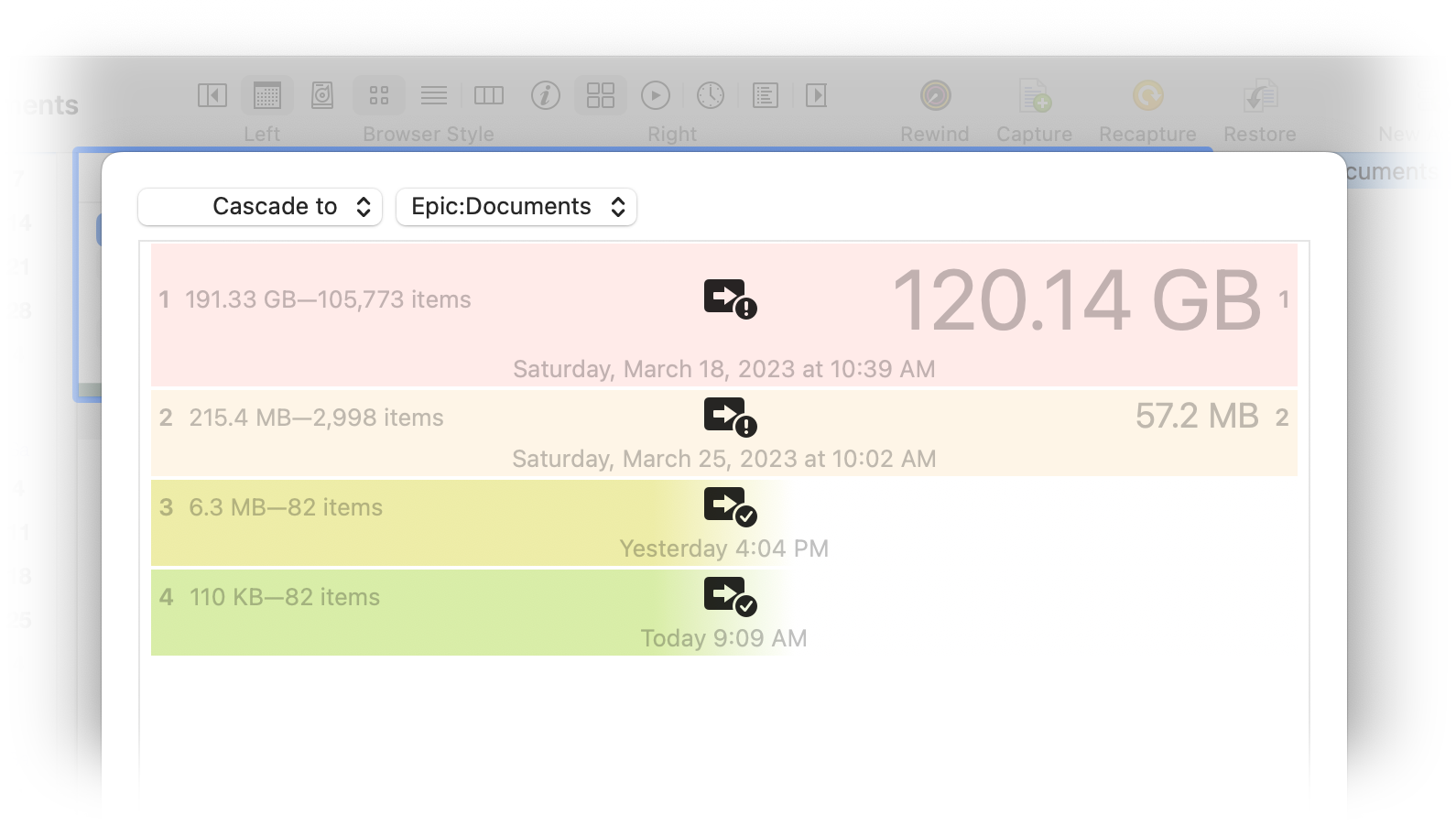
Physically, archives and stacks are stored quite differently.
An archive is a database consisting of a handful of large files that get repeatedly modified.
A stack consists of discrete data elements representing the minimum amount of information needed to define each layer. These elements are stored in the stack container as either data objects or separate files.
That arrangement makes it possible to synchronize the stack with updated layers from the archive by replacing a specific set of data objects/files and nothing more. This minimizes the amount of data necessary to copy to the stack to update it.
You begin by creating a stack for your archive and configuring its settings.
Define a cascade action to regularly update the stack and keep it in sync with the archive. You can also audit the stack container to make sure it is OK.
Should your archive ever become lost of damaged, recover the archive from the stack.